Ok, this has been a bit of a ramble through the development stack to get to this point, but we’re nearly there, honest… for those joining at this point, I’m exploring the ability to succinctly inject test data sets into my JUnit test cases (running DynamoDb in a LocalStack container).
In fact we’re so nearly there he’s a little sample of what we’ll get at the end:
@Test
@DataSet(entity = CustomerPreferences.class, source = "/data/test/customerpreferences/single.json")
public void testSingleLoad() {
//Test code here
}Hopefully that’s succinct enough that you can pick up what its going to do purely from that, and that it’s interesting enough that you’ll want to wander through the rest of this post to see how it works. (if not, don’t worry, there’s a link to my GitHub at the bottom of this post).
Making an Annotation
Since all this is predicated on having an annotation to do the definition of our datasets, we better actually define it:
@DataSet Annotation
@Retention(RetentionPolicy.RUNTIME)
@Target(ElementType.METHOD)
public @interface DataSet {
/**
* Data Entity represented by test data set.
* @return class encapsulated by data set
*/
public Class<?> entity();
/**
* Resource path to data set accessible on classpath.
* @return Resource path to data set accessible on classpath.
*/
public String source() default "";
/**
* Indicates if the data set contains multiple instances of the represented entity.
* @return true if multiple occurrences exist, false if only one is represented.
*/
public boolean multiple() default false;
}This lets us define:
- A Class file which encapsulates our data set
- This needs to be annotated with the @DynamoDbTable annotations that are used to support the DynamoDbMapper
- Path to a Json file on our class-path containing the result set we want to load
- A flag indicating if a single record or multiple is being added
Testing Framework
That’s not a lot of code above to actually get sample data sets we’ve written in Json populated into a local docker container running DynamoDb, but that’s because we’ve had to move the complexity somewhere else, namely into a framework of annotation processors and helper classes:
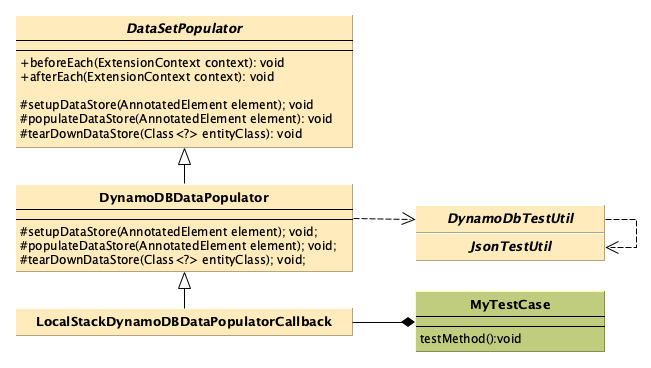
Class Diagram of the Test Framework we’re going to build here
That might seem overkill in terms of abstraction for a single use case, but I’ve also extended this so that I can target other data repositories that aren’t DynamoDb, and I can reuse the same test case approach and just switch the annotation processor to flip the tests between DynamoDB, and my in-memory data source (assuming the test code can cope with that, which in my cases they can).
Annotation Processor
Leveraging the JUnit5 extension capability to add in a communal BeforeEach and AfterEach methods is really the key to what we’re doing here, so our test cases start to look like this:
@RunWith(LocalstackTestRunner.class)
@ExtendWith({
LocalstackDockerExtension.class,
MyAnnotationProcessor.class
})
@LocalstackDockerProperties(
services = { "dynamodb" },
useSingleDockerContainer = true
)
public class MyTestCase {
//Test methods here
}The new addition we’ve got here is MyAnnotationProcessor.class (insert better name in next example…). This actually implements our BeforeEach and AfterEach methods for us rather than having to copy paste or setup static initialisers:
DataSetPopulator Annotation Processor
public abstract class DataSetPopulator implements BeforeEachCallback, AfterEachCallback {
@Override
public void beforeEach(ExtensionContext context) throws Exception {
Optional<AnnotatedElement> element = context.getElement();
if (element.isPresent()) {
AnnotatedElement c = element.get();
if (c.isAnnotationPresent(DataSet.class)) {
setupDataStore(c);
populateDataStore(c);
}
} else {
throw new IllegalArgumentException("Provided entity context does not provide lifecycle element");
}
}
@Override
public void afterEach(ExtensionContext context) throws Exception {
Optional<AnnotatedElement> element = context.getElement();
if (!element.isPresent()) {
throw new IllegalArgumentException("Provided entity context does not provide lifecycle element");
}
AnnotatedElement e = element.get();
DataSet annotation = e.getAnnotation(DataSet.class);
tearDownDataStore(annotation.entity());
}
protected abstract void setupDataStore(AnnotatedElement c);
protected abstract void populateDataStore(AnnotatedElement c);
protected abstract void tearDownDataStore(Class<?> entity);
}I like to make sure that each of my tests are totally isolated in independent of each other, if I knew that all of my tests were idempotent I could have done this as a BeforeAll/AfterAll approach, but I like the flexibility to swap different data sets between methods rather than mix in irrelevant datasets into my test (that’s what integration testing is for).
That means that before each method, I’m creating a new data storage area (or a table), if I’ve provided a sample file it will load it into the data store and after each method I’m tearing down the data store again to make sure we’re ready to go again for the next test.
Few more code samples, and that’s the actual implementation of this for DynamoDb:
Setting up a DynamoDB DataStore
@Override
public void setupDataStore(AnnotatedElement e) {
DataSet dataSet = e.getAnnotation(DataSet.class);
DynamoDBTestUtil.createTableFor(
getDynamoDBDataSource().getConnection(),
dataSet.entity()
);
}Tearing down the DynamoDb DataStore
@Override
protected void tearDownDataStore(Class<?> entityClass) {
DynamoDBTestUtil.deleteTableFor(
getDynamoDBDataSource().getConnection(),
entityClass
);
}Better make sure to actually populate that table:
Populating a Data Store
@Override
protected void populateDataStore(AnnotatedElement c) {
DataSet dataSet = c.getAnnotation(DataSet.class);
if (dataSet.source() == null || dataSet.source().trim().isEmpty()) {
return;
}
if (dataSet.multiple()) {
DynamoDBTestUtil.loadBatchTestData(
getDynamoDBDataSource().getConnection(),
dataSet.entity().arrayType(),
dataSet.source()
);
} else {
DynamoDBTestUtil.loadTestData(
getDynamoDBDataSource().getConnection(),
dataSet.entity(),
dataSet.source()
);
}
}What I’ve done here, is check the annotation to see if I’ve specified that I should load multiple items or a singular item, that’s primarily because I’m loading the data here as Json and the file structure will be different. I dare say I might push this further into the test utils, but for now that didn’t feel the right level for it and I don’t want to have two populateDataStore methods in case I get implementations that can handle this more gracefully.
I’ve skipped one more code sample here, which is just a wrapper class that populates the Annotation Processor with the connection to my LocalStack DynamoDb container.
JUnit Test cases with @Datasets
And we’re there, our final test class with 3 test cases looks like this:
Final Example
@RunWith(LocalstackTestRunner.class)
@ExtendWith({
LocalstackDockerExtension.class,
LocalStackDynamoDBDataPopulatorCallback.class
})
@LocalstackDockerProperties(
services = { "dynamodb" },
useSingleDockerContainer = true
)
public class DynamoDBDataPopulationTest {
@Test
@DataSet(entity = CustomerPreferences.class)
public void testEmptyLoad() {
Assertions.assertEquals(
0,
DynamoDBTestUtil.countItemsInTable(TestUtils.getClientDynamoDB(), CustomerPreferences.class)
);
}
@Test
@DataSet(entity = CustomerPreferences.class, source = "/data/test/customerpreferences/single.json")
public void testSingleLoad() {
Assertions.assertEquals(
1,
DynamoDBTestUtil.countItemsInTable(TestUtils.getClientDynamoDB(), CustomerPreferences.class)
);
}
@Test
@DataSet(entity = CustomerPreferences.class, source = "/data/test/customerpreferences/multiple.json", multiple = true)
public void testMultipleLoad() {
Assertions.assertEquals(
3,
DynamoDBTestUtil.countItemsInTable(TestUtils.getClientDynamoDB(), CustomerPreferences.class)
);
}
}Link to GitHub repository containing code samples that this series was based on.
And again, this direct implementation wouldn’t be possible without LocalStack and LocalStack-java-util projects, so thank you to the developers over there.
Check out the other posts in this series I’ll come back and provide the links to the follow up posts here once they’ve been updated:
- Development with AWS & LocalStack
- Unit Testing Java and DyanmoDB, with JUnit & LocalStack
- Configuration through Annotation
- Building a @Dataset (This Post)